in the following outlined Stack implemetation everything is
at the same level:

figure 2.1
This page:
http://www.pms.informatik.uni-muenchen.de/publikationen/fopras/Stephanie.Spranger/paper.html
Stephanie Spranger@informatik.uni-muenchen.de,
2001-03-11
Lehr- und Forschungseinheit für Programmier- und
Modellierungssprachen,
Institut für Informatik der Ludwigs- Maximilians-
Universität München
Stephanie Spranger
XML Schema is a significant progress compared to DTDs especially as far as modularization and information hiding are concerned. One might howerver question, what the modularization and information hiding capabilities of XML Schema are compared to that of modern programming and modelling languages. This paper investigates this issue. In addition, it makes a proposal for improving modularization with XML Schema. In a first part, we recall the means for modularization and information hiding with programming and modelling languages. In a second part, we analyze to what extent modularization is possible with today's XML Schema. The results show that structuring and partition of schema's static code is possible. But, considering some XML instance document in conformity with some underlying schema, we reveal a lack of information hiding. That means, today's XML Schema provides only limited means for modularization. To overcome this noticeable limitation of XML Schema and to enable information hiding, a new mechanism concerning not only XML Schema but also XML is proposed.
include mechanismThe purpose of this paper is to investigate how modularization is possible with XML Schema. That means, we investigate its capabilities, figure out its lacks, and suggest some redress for the revealed drawbacks. Since modularization has been thoroughly investigated during the last decades in programming and modelling languages, it is appropriate to first give an overview of modularization in such languages before turning attention to XML Schema.
First we want to explain why it is more worthwhile to consider XML
Schema's modularzation aspects than XML DTD's means for modularization. The
Extensible Markup Language (XML) [XML] serves to describe structured data
items called XML documents , or just documents for short. XML has been
originally developed for modelling structured texts. However XML is not
restricted to textual data, it can also be used for specifying data formats,
e.g. for data interchange between software applications (such as e-Commerce or
Information Systems). In XML, one can specify the structure of a class of
documents using the Document Type Definition (DTD) language [XML].
Unfortunately, DTDs have a number of drawbacks especially concerning
modularization. To overcome them, a new formalism, the language XML Schema
[XMLSch-0], has recently been proposed.
DTDs do not offer much possibilities for modularization: In a DTD
names of elements are independent of the context. That means, if in a DTD an
element named for example address is defined then this address-element
has the same structure in all contexts. That is, indeed DTDs are based upon
context-free grammars. But with XML Schema it is possible to define for example an
address-element that consists of an email-element and a
phonenumber-element if this address-element occurs within a
person-element. The address-element consists of a street-element, a
streetnumber-element and a city-element if the address-element occurs in
a building-element.
If some specifications occur more than once in a DTD the only
mechanism available for sharing this part is that of parameter-entities
[recXML], i.e. a very simple macro formalism. In contrast XML Schema offers an
include mechanism (this mechanism is described in
section 3).
Turning attention to recent activities of W3C: Modularization of XHTML in XML Schema is devoted to modularize the specification of XHTML and not to structured data using XHTML. The modularization of XHTML is desirable for serving its platform independence. However, this issue is not related to modularizing structured data items using a markup language specified in XML Schema.
Nowadays most programming and modelling languages support various
forms of modularization. Modularization supplements a language with several
principles in order to make code easier to comprehend, to make large programs
easier to maintain and thus, to facilitate the reuse of code. Modularized
code consists of several relatively independent units. The working of a
program is the interaction of these units: Some unit may need the service of
other units, thus, there is a dependency relation between these units.
Furthermore, modularization is founded upon the idea of information
hiding, which makes data and operations invisible, whenever possible, to
parts of a program that do not need to refer to them. In that way, properly
modularized code reduces the amount of information required for understanding
any given part of a program.
The characteristic features of some language's module system are
what sort of operation one is able to perform with some unit and how
distribution of code is managed.
In this section we recall the means for modularization in programming and modelling languages. Programming languages offer more advanced means for modularization than modelling languages. Therefore, it is worthwhile to primarily consider modularization in programming languages.
In this section we present several stages in the developement of data abstraction with an emphasis on modularization in programming languages. We begin with procedures. These are followed by modules, which allow a collection of procedures to share a set of static data. Finally, we recall classes which are object factories that define the data and the operations common to all objects of some kind.
Solving a complex problem by dividing it into several parts and
solving each part separately often simplifies the solution of difficult
problems. Furthermore, a subpart occuring at several places in an algorithm
is worth being specified only once. For these reasons, algorithms are divided
into several parts which are specified separately, whenever it is possible.
Procedures are the essential means for such a program partition.
They provide several features: Procedures enable to divide an
algorithm into several parts which can be specified separately. In that way,
the algorithm is easier to specifiy, and thus, easier to comprehend.
Furthermore, procedures enable the reuse of identical parts of a program on
different locations in that program. In this way, implementation and
maintenance of code become easier. That is, procedures are exchangeable
program components. In addition to this, one is allowed to have local
variables accessible only from within a procedure inside which they are
declared. Moreover, variables declared at the top-level, e.g. global
variables, or variables declared in a containing block if the related
procedures are nested, can be used by an arbitrary procedure.
Let us consider the data structure of a stack. A stack has two main
operations: Operation push(elt) adds elt to the stack; the most-recently
added element is removed by the operation pop().
A possibility to design a stack is by defining a collection of
procedures. Then the code must be read as a whole, since all declarations of
the same kind are collected together. In this way, we have a collection of all
constant declarations followed by all types, by all variables, and finally by
all procedures. That is, the procedures defined in that way are all at the same
level. That means that they can call each other. Furthermore, these procedures
are operating on global data.
Let us consider a stack implemented as a collection of procedure
declarations:
in the following outlined Stack implemetation everything is
at the same level:
figure 2.1
Considering the stack program outlined in figure 2.1, it contains a collection
of procedures, and moreover, it consists of a single block. Each of these blocks, in turn,
is a block which can contain other procedures to any depth of nesting. No
device for dividing a program into units that can be compiled seperately is
given.
But, dividing code among several developers in order to work
independently, is a major issue in today`s software engineering.
The idea that data and operations go together to build a natural unit is the basis for designing modules. In general, a module consists of two parts. The first part, called the interface, describes the behavior of the module. The interface can contain constants, variables, datatypes, and procedures. It is observable from outside the module. In the second part of the module, the design decisions, i.e. the implementation details, are hidden. This part is often called implementation. It is only accessible from within the module. The parts interface and implementation are also called public and private (in some programming languages, e.g. Modula2), respectively.
Going again to our stack example of figure 2.1. Considering the above
described module concept, the interface or public part says nothing about the
stack`s structure. In this public part nothing of the implementation is
visible. That means, the representation is hidden in the private part of the
stack. Hiding information in a private part of a program is called
information hiding. An important advantage of information hiding is that
the private part can be changed without interfering with the rest of the
program.
In addition to this, concerning the particular stack implementation in
our stack-example, a pointer to the stack's current top value is necessary. The
pointer should be invisible for the rest of the program. That means, the stack
pointer is only visible inside a certain scope. Keeping these considerations
in mind, the stack module can have a representation as seen in
figure2.2.
A Stack outlined as a module with its public part, i.e. interface, and
its private part, i.e. implementation:
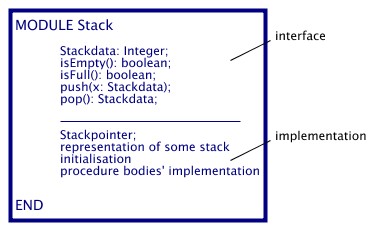
figure 2.2
Furthermore, modules can interact through their interfaces in
accordance with so called import and export rules. An entity that is exported
by some module can be imported by another module.
In some programming languages one is allowed to single out entities of
an interface by using an explicit import clause (e.g. Modula2), or it is
possible to restrict the underlying interface by designing a new interface with
less information visible (e.g. Standard ML or SML). Let us consider the general
working of the import and export rules:
Using an explicit import Creating a new interface derived from
clause: from the underlying interface A:
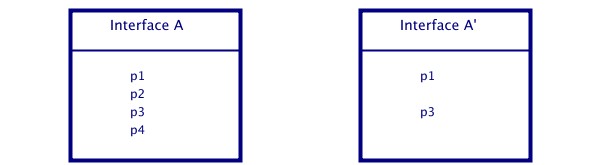
Module B imports Implementation of B' uses A'
A.p1 and A.p3
figure 2.3
As a consequence of the restricting import clause and the interface A' derived by the underlying interface A, respectively, shown in figure 2.3, implementing B and B' some developer has only access to the entities named p1 and p3 within the interface A. In that way, some developer has only access to entities he actually needs to refer to. Thus, one is allowed to control the interaction among several modules by using import and export rules. That means, the information interchange with some underlying interface can be restricted with the benifit of access control. In general, with this import and export mechanism, source code can be easier re-used and maintained. Moreover, the code is easier to comprehend.
Going again to our stack example of figure 2.2, a list may be seen as an extension of a stack. Therefore, in the implementation of the list the stack can be used as seen in the following figure (2.4).
Some List module imports the Stack module outlined in figure 2.2
and has therefore the following outline:
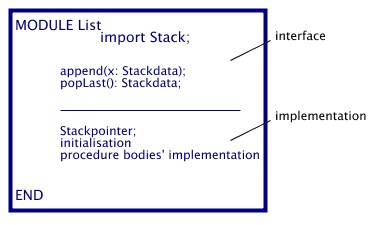
figure 2.4
The import clause, as seen in figure 2.4, allows the List in the implementation part to use declarations stated in the interface of the Stack module. One benefit of distributing the implementation of the Stack and the List among two modules is to reduce the risk of name conflicts. Furthermore, it raises the integrity of data abstraction and moreover, the modularization increases reuse of code (i.e. the List's module uses code implemented in the Stack's module).
As we have seen in the discussion above, modules basically provide
collections of procedures and related data and moreover, the ability of
importing and exporting several modules using their related interfaces.
But going again to our stack-module, shown in figure 2.2: What happens if the
programming task requires more than one stack? For such an application, we
must either replicate the code or we must expand the code with a manager
module in order to manage instances of a stack type.
Yet, another possibility to solve the multiple instance problem can be
found in defining some abstract data type, which is similar to a module, but
treated as a type. Thus, some code developer has the ability to instantiate
an arbitrary number of similar objects of a given type.
Working out the distinction, an ordinary module needs a manager for
its instances, but using module types instead, some module itself can be the
abstract data type. In that way, the explicit create procedure for creating
an object from a manager module is replaced by creating an instance of some
module type.
As an extension of the module-as-type approach today's programming
languages often provide a class construct for object-oriented programming.
In a first approximation, classes can be thought of as module types augmented
by inheritance. With inheritance some developer is allowed to define a new
class as extension or as restriction, respectively of an existing class. For
this purpose, classes are organized in a single-rooted tree structure known as
inheritance hierarchy. In that way, information (e.g. state and behavior)
associated with one level of abstraction in a class hierarchy is automatically
applicable to lower levels of the underlying inheritance tree.
An instance of a class is known as an object. Thus, a class is an
object factory for similar objects. These objects perform computation by making
requests of each other through passing messages (i.e. method call). Further
actions (behavior) are produced in response to requests for messages. An
object may accept a message, and in return it performs some action (i.e.
call some procedure) and returns some value. We can see that message passing
differs from an ordinary procedure call: Passing a message is always
transmitted to a specific object. Then the class of this object decides the
particular method (i.e. procedure) that is invoked. That means, every message
has a receiver, hence it follows, that the interpretation of a message depends
on the underlying receiver (i.e. object). Thus, all objects have their own
methods to be executed in response to an incoming action.
Keeping these considerations in mind, we illustrate the principle of
message passing:
Image and Text are subclasses of the class of Documents:
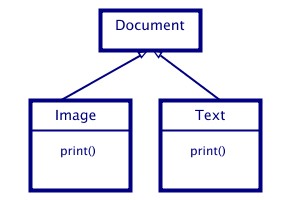
Creating an object of the Image's class: new Image img;
img receives a message (so as to print): img.print()
figure 2.5
The action, as illustrated in figure 2.5, i.e. printing an image, could also be implemented with an ordinary procedure call. Then, there is an important difference compared to message passing: While calling some procedure, the object that is involved must be explicitly associated with its underlying procedure, i.e. calling the procedure print_img(param). That means, in the static code is no hint for the relation between some object and its related action. This relation (between an object and its action) is provided by the object-oriented programming concept which has won information hiding, thanks to message passing.
Turning attention to a further principle of modularization concerning large software projects. Let us assume such a large project consisting of multiple classes. Making these classes easier to find and thus to use, and moreover, to avoid possible name conflicts, developers may group related classes into a package. A package is a collection of classes, considered from the viewpoint of the application to be related, that provides access protection and namespace management. That means, creating packages, some developer can easily see that these classes are considered to be related. Furthermore, classes grouped into a package cannot conflict with class names in other packages, because with the creation of some package a new namespace is generated.
Going again to our stack example, we want to implement the stack and the list as two classes, whereas the class of lists should be a subclass of the class of stacks:
A class hierarchy represating a class of Lists as a subclass
of a class of Stacks:
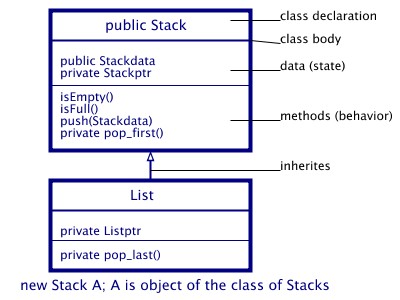
[inheritance and object-oriented conceptions]
figure 2.6
With the introduction of inheritance, object-oriented languages have needed to supplement the visibility rules of module-based languages to cover additional issues for information hiding. For example, should public members of a base class always be visible to users of the class derived by the base class? Let us consider the classes demonstrated in figure 2.6. For example, we have hidden the method pop_first() by using the modifier private in the stack's class and thus, this method is invisible in the class of lists. Another modifier which is used in the example is public. Software components which are declared as public can be used globally. ( In some programming languages (here: Java) one is allowed to have further modifiers: If a component has no modifier, then it is visible within the class and the package they are declared within. Using a further modifier, namely protected, the components are additionally visible in all subclasses, even though they are not declared inside the same package.) In general, as we have seen previously, software components have a public face and a private face. Inheritance introduces further alternatives based on the ability of creating subclasses.
In this section we have seen that with programming languages supporting modularization some program can be developed using different design decisions. That is, a program can appear as a collection of procedures, a program can contain several modules or a program can be designed object-oriented. In each case, the size of code is nearly the same. The difference among the approaches is the support for modularization. Thus, modularization is a powerful technique for increasing comprehention, reusability, and maintenance of code, because seperating the properties of a data type from the details of its implementation frees the user of that type from having to write code that depends on a particular implementation of that type.
The XML Schema language allows the formulation of so called
schemas. (Schemas are similar to database schemas although XML Schema's
structure is much richer than the structure of the schemas of most database
systems.) A schema formulated in the language XML
Schema[XMLSch-0]
has itself the
syntactic form of an XML document. Whenever a strict distinction between a
schema document and a document that conforms to some schema is relevant, the
former is usually called schema document or schema for short, the
latter instance document. In the
following section, we use the terms schema and instance document or
instance for short.
In general, a schema consists of schema components such as
declarations and definitions, which specify the allowed structure of
XML instance documents in conformity with some underlying schema. In XML Schema the
creation of a new type is called a definition. Elements and attributes of some
type can be declared. The declaration of elements and attributes in
a schema allows them to appear in an instance document conforming to this
schema. However, these declarations and definitions can be either global, i.e. as
children of the schema element[InfoSet], or local to some
other declaration or definition.
From the point of view of programming languages, a schema corresponds
to the declaration of data structures in a program, and an XML instance document
corresponds to the actual data used by the program at run time. As already
discussed above in the previous section, it is widely accepted that programming
languages offer many means for modularization rather than requiring a program and
its declarations to be organized in one big monolithic piece. Programming
languages using modularization are easier to comprehend and their code is easier to
maintain. Furthermore, properly modularized code can be reused.
Similar advantages like the ones discussesd in section two would seem to apply
to schemas if the XML Schema language in which schemas are formulated would provide the
necessary principles (e.g. a convenient mechanism) to support modularization.
In the following section the principles that XML Schema is using to
achieve modularization are discussed. During this
investigation, we reveal some lack of information hiding when
creating some XML instance document conform to some underlying schema.
To finally overcome this drawback, possible extensions concerning the XML Schema
language and the language XML, and thus, an improved
modularization with XML Schema is suggested.
In this section we recall the notion of target namespace in XML
Schema and its use. Moreover, schema distribution among several files is
discussed. Furthermore, we explain the possibilities to support
modularization in XML Schema by using these features. Finally, a discussion
on grouping of schema components and schemas is presented.
The XML Schema term for a building block that is a constituent
of a schema's data model is schema component (e.g. a
complex type definition or an element declaration)[XMLSch-1]. A
schema is a collection of schema components. Several kinds of schema
components might have a common target namespace. This target namespace is either
absent, or it is the URI of a namespace, as defined
by XML Namespace [XNR]. If no target namespace is explicitely
specified, then there is no hint to the physical location of the related
schema documents. The target namespace serves to identify the namespace within
which the association between the schema component and its name exists. That
means, schema components can be located, as illustrated in figure 3.1,
within a target namespace.
Schema components can be put together to a schema and schemas can be
put together in a single target namespace. That means, target namespaces are
an XML mechanism to group different schemas together. That is, the schemas,
containing various schema components, grouped together in a namespace form a
module that can be reused in another context. In that way, the data structure
created by using XML Schema might become easier to maintain.
In this figure the relations among schema components, schemas and target
namespaces are illustrated.
assuming a namespace for the following illustration:
xmlns:ex1="http://www.example1.com/schemaA_B_C"
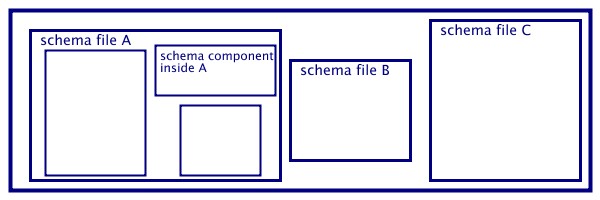
for example a schema component (with name="compA") inside schema file
A can be located using ex1:compA
figure 3.1
include mechanism of XML Schema
The distribution of a schema among several files is nothing more than a
mere partition of the schema's static code. This can be useful for reasons
of comprehension and maintenance and to facilitate cooperation among a group
of developers. Nevertheless, these distributed schema files which are
located in the same target namespace may be used together. XML Schema provides
the include mechanism in order to assemble distributed schema files. Only
schemas within the same target namespace can be put together using the
include mechanism (i.e. can be included) because the include mechanism
cannot locate different namespaces. This restriction of the include
mechanism is desired, because the include mecanism should help assembling
related schemas. That means, include is a convenient mechanism to support
the module structure of XML Schema's namespace principle. Furthermore, the
include mechanism serves to work out associations among including and
included schema files. The include mechanism is
illustrated in figure 3.2.
In this figure the relations among include mechanism, target namespaces
and schemas are illustrated.
assuming following namespaces for the two illustrations:
xmlns:ex1="http://www.example1. xmlns:ex2="http://www.schemaDE.
com/schemaA_B_C" com/example2"
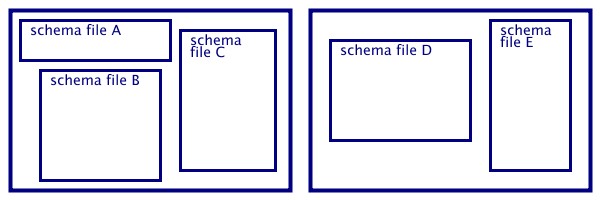
using the include mechanism it is possible to produce any
combination of A, B and C (as long as there is no redundancy); but it
is not possible to include, for example, A within D
figure 3.2
Let us consider a schema for reports that contains a title page (with personal data about the author), an outline for the report and references to literature. This schema might become too large to be kept in one schema file. It is thus desirable to distribute the components of the complete schema between two (or among more) schema files. Therefore, as shown in figure 3.3, in the report.xsd schema file an auxiliary schema file references.xsd holding all components of the schema concerning the title page and the references, is included:
content of schema file report.xsd:
<?XML version="1.0" encoding="ISO..." ?>
<schema xmlns ="http://www.w3c.org/1999/XMLSchema"
xmlns:exp ="http://www.project.com/report.xsd"
targetNamespace ="http://www.project.com/report.xsd"
elementFormDefault="qualified">
<include schemaLocation="http://www.project.com/references.xsd/>
<element name="report" type="exp:acamReport"/>
<complexType name="acamReport">
<element name="cover" type="exp:coverType" minOccurs="1"
maxOccurs="1"/>
<element name="title" type="string" minOccurs="1"
maxOccurs="1"/>
<element name="introduction" type="exp:introResultType"
minOccurs="1" maxOccurs="1"/>
<group ref="exp:chapterGroup" minOccurs="1"
maxOccurs = "unbounded"/>
<element name="references" type="exp:refType" minOccurs="1"
maxOccurs="unbounded"/>
</complexType>
<element name="text" type="string"/>
<complexType name="introResultType">
<element name="headline" type="string" minOccurs="1"
maxOccurs="1"/>
<element ref="exp:text" minOccurs="1"/>
</complexType>
<group name="chapterGroup" >
<sequence>
<element name="headline" type="string" />
<element ref="exp:text" />
<element name="headline2" type="string" minOccurs="0"
maxOccurs = "unbounded"/>
<element ref="exp:text" minOccurs="0"/>
<element name="headline3" type="string" minOccurs="0"
maxOccurs ="unbounded"/>
<element ref="exp:text" minOccurs="0"/>
</sequence>
</group>
</schema>
------------------------------------------------------------------
content of schema file references.xsd:
<?XML version="1.0" encoding="ISO..." ?>
<schema xmlns ="http://www.w3c.org/1999/XMLSchema"
xmlns:exp ="http://www.project.com/report.xsd"
targetNamespace ="http://www.project.com/report.xsd"
elementFormDefault ="qualified">
<complexType name="refType">
<choice>
<element name="onlineRef" type="uriReference"/>
<group ref="exp:book"/>
</choice>
</complexType>
<group name="book">
<sequence>
<element name="title" type="string"/>
<element name="author" type="string"/>
<element name="publishers" type="string"/>
<element name="published" type="year"/>
</sequence>
</group>
<complexType name="coverType">
<element name="title" type="string" minOccurs="1"
maxOccurs="1"/>
<element name="name" type="string" minOccurs="1"
maxOccurs ="1"/>
<element name="profession" type="string" minOccurs="0"
maxOccurs="1"/>
<element name="affiliation" type="string" minOccurs="0"
maxOccurs="1"/>
<element name="published" type="date" minOccurs="1"
maxOccurs="1"/>
</complexType>
</schema>
An instance conform to the schema file report.xsd that includes the file
references.xsd:
<report>
<cover>
<title>Modularization with XML Schema</title>
<name>Stephanie Spranger</name>
<published>???</published>
</cover>
<title>Modularization with XML Schema</title>
<introduction>
<headline>1. Introduction</headline>
<text>...</text>
</introduction>
<headline>Modularization with programming and modelling
languages</headline>
<text>...</text>
<headline2>2.1 Forms of modularization</headline2>
<text>...</text>
<headline3>2.1.1 Procedures</headline3>
<text>....</text>
<headline3>2.1.2 Modules</headline>
<text>....</text>
<headline3>2.1.3 Classes</headline3>
<text>... </text>
...
<references>
<onlineRef>http://www.w3.org/TR/xmlschema-1</onlineRef>
...
</references>
</report>
figure 3.3
In the schema, that is shown in figure 3.3, the components of the
report-schema (outline of a report, data concerning the author) are
distributed over two schema files (the file report.xsd and references.xsd).
The effect of the use of the include mechanism in the schema file
report.xsd is to bring in the schema components (i.e. various definitions and
declarations) contained in the schema file references.xsd and make them
available as part of the schema file report.xsd. All schema components of
the schema file refernces.xsd along with their attribute and local element
declarations are visible within the schema file report.xsd. In this way, the
declarations and definitions of the included and the including schema files
are merged and a single schema is created.
That means, distributing schema files within the same namespace
serves to make schemas easier to maintain and increases readability.
Furthermore, it is also possible to include more than one schema file, and
the inclusion of schema files can be nested.
Combining schemas which are within different namespaces is illustrated
in section 3.4 (deals with information hiding). Combining schemas within different
namespaces is left to global schema components. That is, nothing more can
explicitely be exported by some namespace.
This section is a discussion, how grouping of schema components can help manage collections of schema components. For this purpose, we illustrate issues such as nesting of schema components and deriving some new type from some underlying base type in order to explain the structuring possibilities of the XML Schema language.
In XML Schema it is possible to put a sequence of element and/or
attribute declarations as children of the schema element. Such declarations
are known as global. The scope of the global declarations is the schema inside
which they are declared.
Let us consider the references.xsd schema that has been introduced
in the previous section. A possibility to create this schema is to declare a
sequence of elements and an attribute:
content of schema references.xsd:
<xsd:schema>
<xsd:element name="onlineRef" type="xsd:uriReference"/>
<xsd:element name="title" type="xsd:string"/>
<xsd:element name="author" type="xsd:string"/>
<xsd:element name="publishers" type="xsd:string"/>
<xsd:element name="published" type="xsd:year"/>
<xsd:element name="title" type="xsd:string" minOccurs="1"
maxOccurs="1"/>
<xsd:element name="name" type="xsd:string" minOccurs="1"
maxOccurs ="1"/>
<xsd:element name="profession" type="xsd:string" minOccurs="0"
maxOccurs="1"/>
<xsd:element name="affiliation" type="xsd:string" minOccurs="0"
maxOccurs="1"/>
<xsd:attribute name="published" type="xsd:date" minOccurs="1"
maxOccurs="1"/>
</schema>
figure 3.4
The declarations seen in figure 3.4 are all global and at the same
level. That is, they can refer to each other and also they can be referred to
by another schema. Moreover, they can appear in an instance document, because
the XML Schema language allows only the use of global declarations in an
instance document [XMLSch-1].
Unfortunately, creating a schema as a mere sequence of declarations
is not a good design practice, as it makes it difficult to reuse (part or
all of) the schema. Also it makes the schema more difficult to comprehend,
because the semantic partitioning is lost if the schemas are a sequence of
simple declarations.
Yet another possibility to create a schema would be to put several
schema components inside another schema component. That is, grouping several
simple schema components in order to create a single complex component that
can be used instead. In this complex schema component the contained
components are local and their scope is the schema component within which they
are put. That means, these local schema components are hidden inside (where
they are created) from all other schema components created outside.
Let us consider the schema references.xsd. Compared with the
schema's structure as seen in figure 3.4, the same declarations are now
grouped within different schema components in order to create a more
structured schema that is shown in figure 3.5.
content of file references.xsd:
<xsd:schema>
<xsd:complexType name="refType">
<xsd:choice>
<xsd:element name="onlineRef" type="xsd:uriReference"/>
<xsd:group ref="exp:book"/>
</xsd:choice>
</xsd:complexType>
<xsd:group name="book">
<xsd:sequence>
<xsd:element name="title" type="xsd:string"/>
<xsd:element name="author" type="xsd:string"/>
<xsd:element name="publishers" type="xsd:string"/>
<xsd:element name="published" type="xsd:year"/>
</xsd:sequence>
</xsd:group>
<xsd:complexType name="coverType">
<xsd:element name="title" type="xsd:string" minOccurs="1"
maxOccurs="1"/>
<xsd:element name="name" type="xsd:string" minOccurs="1"
maxOccurs ="1"/>
<xsd:element name="profession" type="xsd:string" minOccurs="0"
maxOccurs="1"/>
<xsd:element name="affiliation" type="xsd:string" minOccurs="0"
maxOccurs="1"/>
<xsd:attribute name="published" type="xsd:date" minOccurs="1"
maxOccurs="1"/>
</xsd:complexType>
</xsd:schema>
figure 3.5
Grouping declarations as shown in figure 3.5, has as a consequence
that, whenever an instance document conform to this schema is produced, any
element appearing in that instance document whose type is, for example,
coverType must contain the elements title and name, and can contain the
elements profession, and affiliation (because they have an attribute
minOccurs with value 0). Moreover, this instance must contain an attribute, namly
published. Unlike the declarations in figure 3.4, these elements and that
attribute are declared locally inside the complex type coverType.
Let us consider a possible instance document that contains an element
of the type coverType:
Assuming that an element with the name cover of the type coverType
is declared in the schema shown in figure 3.5. Then, the following element
can appear in an XML instance document that is conform to this schema:
<cover published="May 1996">
<title> Programming languages </title>
<name> Ravi Sethi </name>
</cover>
figure 3.6
Furthermore, it is not only possible to put schema components into global schema components, as illustrated in figure 3.5, but it is also possible that local schema components contain further ones. Thus, schema components are nested in order to be hidden inside other specific schema components. In that way, schema components can be created and edited in one place and referenced and reused in multiple different schema components. That means, grouping schema components improves the reuse in XML Schema. Furthermore, a schema that contains not only sequences of global declarations, but also schema components which are put together inside other ones, is easier to comprehent. Moreover, referring to schema components makes schemas easier to maintain. That is, we have seen that grouping schema components is an attempt to manage schemas with many schema components. Grouping schema components in the above described way is possible with today's XML Schema.
To build a hierarchical type structure in XML Schema, it is possible
to create new complex types derived by an existing types that is called base type.
A new type contains the schema components of the base type and some new
components are added on the base type. Alternatively, a new type can be
created by restricting the underlying base type. In that way, the base type
is reused.
Let us consider the example shown in figure 3.7. The derivedBy
schema attribute is used to extend the Address type that is created within
that schema:
Example for deriving types from existing types by extension:
<xsd:schema>
<xsd:complexType name="Address">
<xsd:element name="firstname" type="xsd:string"/>
<xsd:element name="name" type="xsd:string"/>
<xsd:element name="street" type="xsd:string"/>
<xsd:element name="city" type="xsd:string"/>
<xsd:element name="postcode" type="xsd:decimal"/>
<xsd:attribute name="country" type="xsd:NMTOKEN"/>
</complexType>
<xsd:complexType name="StudentLMU"base="Address" derivedBy="extension">
<xsd:element name="field of study" type="xsd:string"/>
<xsd:element name="term">
<xsd:simpleType base="xsd:decimal">
<minInclusive value="1"/>
<maxInclusive value="19"/>
</xsd:simpleType>
</xsd:element>
<xsd:element name="matrNum">
<xsd:simpleType base="xsd:string">
<pattern value =
"0[1-9]|[12][0-9]|30|31(0[1-9]|10|11|12)\d{2}\d{6}"/>
</xsd:simpleType>
</xsd:element>
</xsd:complexType>
</xsd:schema>
figure 3.7
With using the extension value for the derivedBy attribute it is
possible to add further schema components to an existing schema component as
seen in figure 3.7. The example in figure 3.7 shows how deriving of schema
components in order to reuse user-defined schema components in XML Schema
works. That is, the studentLMU type is derived from the Address type, and
thus, the new schema component contains the components put together in the
address type, and further components, namely subject, term, and matrNum
put within the studentLMU type. In that way, a hierarchical schema component
structure (with an arbitrary depth) is possible with XML Schema. This mechanism
allows for reusability and better comprehension of the produced schemas.
On the opposite, it is also possible to restrict the underlying base
type. Then the new type contains less schema components than the base type.
That means, if using a restriction, the values represented by the new type
are a subset of the values represented by the base type.
It has to be noted that the use of derived types may be supressed
using the XML Schema final mechanism. With that
mechanism the derivation of types can
be prevented. Moreover, if the use of a derived type should be supressed in an
instance document the XML Schema mechanism block can be used. In this case,
only an element of the underlying base type can be used in an instance because
the derived type is blocked.
Having discussed how deriving types works so as to create new types, let us consider an instance document that conforms to a schema containing some derived type. Therefore, we create an instance document that conforms to the schema seen in figure 3.7:
We assume that an element address of type Address and an element
student of type StudentLMU are created in the schema seen in
figure 3.7. Then it is possible to create an instance conform
to the schema presented in figure 3.7 as follows:
<address country="Germany">
<firstname> Hans </firstname>
<name> Mayer </name>
<street> Kirchenstrasse </street>
<city> München </city>
<postcode> 81365 </postcode>
</address>
<student country="Germany">
<firstname> Hans </firstname>
<name> Mayer </name>
<street> Kirchenstrasse </street>
<city> München </city>
<postcode> 81365 </postcode>
<field of study> Informatik </field of study>
<term> 11 </term>
<matrNum> 121268398123 </matrNum>
</student>
figure 3.8
In figure 3.8 it is shown, that the element student of type StudentLMU contains also the components put together in the underlying base type Address and the components added on the derived type StudentLMU.
In the dicussion of this section we have seen, that schemas as defined in XML Schema can be created by using different design decisions. That is, a schema can appear as a sequence of simple declarations, a schema can contain nested schema components, or one can create a hierachical schema component structure. In each case, the amount of schema code is almost the same. Essentially, the same simple schema declarations have to be written. The difference among the approaches are in the support for structuring schemas and for having that structure be profitable for some reader and some other designers. Actually, modularization requires for some possibility of structuring code.
This section is a discussion about a possible mechanism that could be
added to XML Schema, and in relation with it, a suggested mechanism for XML so as to support information hiding with XML Schema. First,
we illustrate XML Schema's import mechanism, which is used to make schemas
available within different target namespaces. Then, it is discussed, why XML
Schema does not support information hiding. Finally, we suggest a possible
extension of XML Schema and XML so as to support information hiding. Information
hiding is desirable in XML Schema, because inconsistency of modified
schemas and its related XML instances can be prevented.
Consider the following example shown in figure 3.9 in which a schema containing schema components representing student data of a university is described:
content of the student schema:
<?XMLversion="1.0" encoding="ISO..." ?>
<xsd:schema targetNamespace= "http://www.uni-muenchen.de/student"
xmlns ="http://www.w3c.org/1999/XMLSchema"
xmlns:stud ="http://www.uni-muenchen.de/student">
<element name="studentLMU" type="stud:StudentLMU/>
<complex type name="Address">
<element name="firstname" type="string"/>
<element name="name" type="string"/>
<element name="street" type="string"/>
<element name="city" type="string"/>
<element name="postcode" type="decimal"/>
<element name="country" type="string"/>
</complexType>
<complexType name="StudentLMU">
<element name="address" type:"stud:Address"/>
<element name="field of study"type="string"/>
<element name="term">
<simpleType base="decimal">
<minInclusive value="1"/>
<maxInclusive value="19"/>
</simpleType>
</element>
<element name="matrNum">
<simpleType base="string">
<pattern value =
"0[1-9]|[12][0-9]|30|31(0[1-9]|10|11|12)\d{2}\d{6}"/>
</simpleType>
</element>
</complexType>
</schema>
figure 3.9
The schema as shown in figure 3.9 is part of a given namespace, namely http://www.uni-muenchen.de/student. The global schema components, in this case the complex types Address and StudentLMU and the element studentLMU are associated with the target namespace used in that schema as demonstrated in figure 3.9.
Now consider a professor of that university who wants to use this
schema structure from the student office for his own schema which is within
a different target namespace, namly http://www.informatik.lmu.de/prof/student. In
this case, he is not able to use the include mechanism since namespaces
cannot be located using include. In order to hold various schemas within
different target namespaces together, XML Schema provides the import
mechanism. However, only global schema components can be imported because
local declarations and local, anonymously defined types (e.g. the simple type
relating to the matrNum element seen in figure 3.9) are not associated
with a namespace. That is, the professor can only use the Address and the
StudentLMU type, and thus, he can only refer to the studentLMU element. All
the other element declarations and type definitions are local and therefore
invisible outside the schema components within which they are defined.
The professor imports the student schema, as seen in figure 3.9,
and uses the StudentLMU type in his schema as a base type, as demonstrated in
figure 3.10, and creates a new type, which extends the imported base type with
two additional elements, namely lecture and mark:
content of the "prof/student" schema:
<?xml version="1.0" encoding="ISO..." ?>
<schema targetNamespace = "http://www.informatik.lmu.de/prof/student"
xmlns ="http://www.w3c.org/1999/XMLSchema"
xmlns:pro ="http://www.informatik.lmu.de/prof/student"
xmlns:stud ="http://www.uni-muenchen.de/student">
<import namespace="http://www.uni-muenchen.de/student"/>
<element name="myStudent" type="pro:MyStudents"/>
<complexType name="MyStudents" base="stud:StudentLMU"
derivedBy="extention">
<element name="lecture" type="string"/>
<element name="mark" type="decimal"/>
</complexType>
</schema>
figure 3.10
To create the new type MyStudents as shown in the schema in figure
3.10 by extending the imported studentLMU type, the professor does not need
to know the structure and the elements inside that complex base type. In this case, only the name
must be visible, if he wants to use a certain component.
Usually, a schema is used to create instance documents which
conform to some underlying schema. Using the new type MyStudents, the
professor declares an element myStudent as part of his schema. Then the
following instance document shown in figure 3.11 would conform to the
professor's modified schema seen in figure 3.10:
An XML instance document in conformity with the schema shown in figure 3.10:
<?xml version="1.0">
<pro:myStudent
xmlns:xsi='http://www.w3.org/1999/XMLSchema-instance'
xmlns:pro="http://www.informatik.lmu.de/prof/student" >
<firstname> Hans </firstname>
<name> Mayer </name>
<street> Kirchenstrasse </street>
<city> München </city>
<postcode> 81365 </postcode>
<field of study> Informatik </field of study>
<term> 11 </term>
<matrNum> 121268398123 </matrNum>
<lecture> Programming Languages </lecture>
<mark> 2 </mark>
</myStudent>
figure 3.11
In order for the professor to generate an instance document which
conforms to his created schema, like the one seen in figure 3.11, he has
to know the structure of the imported schema components, because he has to
instantiate these components in the XML instance document conforming to the prof/student-schema. That is, grouping of schema
components in order to hide them in some other components does not support
information hiding when creating some instance document conform to some
underlying schema.
Yet, especially on the level of instance documents in conformity with some schema information hiding
would bring great benefits regarding reuse and derivation of schema
components within different namespaces. In that way, it would be possible to
reduce workload and avoid code errors. Furthermore, modifications of related
schemas can become inconsistent, due to the lack of information hiding.
In the following discussion, we introduce a possible extension of XML Schema and XML in order to support information hiding. At first, this extension is illustrated on an example.
Starting again with the previous example 3.10, the professor wants to
extend an imported type within the schema of the student office as shown in
figure 3.9. Therefore, he uses the XML Schema import mechanism. In addition,
he imports a local element which is located inside the type he wants to extend.
This local element should serve as a key when creating an instance document
that instantiates the extended type. The key is used to identify the already created
instances conform to the underlying base type (defined in some imported schema). This is explained more detailed further below.
The professor uses the matrNum element within the StudentLMU type
as his key element:
Suggested extension of XML Schema's import-mechanism:
content of the "prof/student" schema:
<?xml version="1.0" encoding="ISO..." ?>
<schema targetNamespace = "http://www.informatik.lmu.de/prof/student"
xmlns ="http://www.w3c.org/1999/XMLSchema"
xmlns:pro ="http://www.informatik.lmu.de/prof/student"
xmlns:stud ="http://www.uni-muenchen.de/student">
<import namespace="http://www.uni-muenchen.de/student"/>
<import namespace="http://www.uni-muenchen.de/student.xsd#xpointer(
schema/ex:complexType[@name="StudentLMU"].child(4,matrNum))"/>
<element name="myStudent" type="pro:MyStudents"/>
<complexType name="MyStudents" base="stud:StudentLMU"
derivedBy="extention">
<element name="lecture" type="string"/>
<element name="mark" type="decimal"/>
</complexType>
</schema>
For this new import mechanism it is possible to use XPath [recXPath].
figure 3.12
In order to create an instance document in conformity with the schema seen in figure 3.12, the professor uses only the additional elements (the mean elements of the extended type) and the key element, in this example matrNum, which he must explicitly import before he can use it. Furthermore, he imports instance documents conforming to the schema of the student office:
The proposed import-mechanism for XML can be used as follows:
<?xml version="1.0">
<import namespace="http://www.uni-muenchen.de/student-instance"/>
<pro:myStudent
xmlns:xsi='http://www.w3.org/1999/XMLSchema-instance'
xmlns:pro="http://www.informatik.lmu.de/prof/student">
<matrNum> 121268398123 </matrNum>
<lecture> Programming languages </lecture>
<mark> 2 </mark>
</myStudent>
figure 3.13
We can see that now for creating instance documents which are conform
to the underlying schema, the professor no longer needs to know the structure
of the local components within the StudentLMU type he has imported and
extended for his own application, in contrast to the possibilities of XML
Schema.
Furthermore, the professor obtains the conformed instance document
which already contains the applied components declared locally in the imported
student schema. That means that, the instance document is generated
automatically supported by this new import mechanism in the instance
document created by the professor, seen in figure 3.13. Moreover, the key
element is used to identify the corresponding instance components in the
instance documents created by the student office. These instance components
filtered by using this key are now automatically put in the professor's
instance document using this new import mechanism:
<myStudent>
<firstname> Hans </firstname>
<name> Mayer </name>
<street> Kirchenstrasse </street>
<city> München </city>
<postcode> 81365 </postcode>
<field of study> Informatik </field of study>
<term> 11 </term>
<matrNum> 121268398123 </matrNum>
<lecture> Programming languages </lecture>
<mark> 2 </mark>
</myStudent>
figure 3.14
From the previous example is clear that the proposed
import mechanism for XML and the extension of XML Schema's import mechanism allows information hiding when creating some instance
document conform to some underlying schema that has imported another schema. In that way, we fully use the
advantages of structuring schemas. In fact, the imported instance documents
are identified using an explicitly defined key (that is an imported and
locally declared element) thus automatically generating the particular
instance document.
For that purpose, we suggest an import mechanism for XML. In that way, it is possible
to import existing instance documents (in conformity with some underlying schema)
whereas their structure is hidden. Furthermore, so as to select, and thus, to localize the
used instance documents, an extension of XML Schema's import mechanism
is proposed. This extended mechanism enables importing the mean key-element.
The above described functionality would surely be desirable
and would be very useful. It is not present in the current XML Schema language.
The advantages of the approach described above are:
reduction of workload and code errors and moreover, modifications
become consistent.
In this paper we have studied XML Schema's capabilities for modularization and information hiding compared to that of modern programming and modelling languages. Therefore, we have first recalled the mean possibilities of modern programming and modelling languages. Then, we have shown that schemas formulated in the XML Schema language support modularization using different structuring mechanisms. Nevertheless, we have revealed that some structured schema cannot be taken into account when creating some instance document in conformity with some imported schema, because XML Schema provides no possibilities for information hiding. In that way, modularization with XML Schema allows only for some simple structuring of the schema's static code. To overcome this problem, and thus, to fully use the capabilities of structured schemas, we have proposed a new import mechanism for XML and a therewith related an extension of XML Schema's import mechanism, not present in the current specifications. These two related functionalities are easy to incorporate into XML Schema and XML, respectively. Both import mechanisms together enable information hiding. That is, modularization with XML Schema is improved.
[XML-Sch0]XML Schema Part0:Primer, Working Draft,22-September-2000 This version: http://www.w3.org/TR/xmlschema-0-20000922 Latest version: http://www.w3.org/TR/xmlschema-0, W3C Recommondation, 2-May-2001[XML-Sch1]XML Schema Part1:Structures, Working Draft,22-September-2000 This version: http://www.w3.org/TR/xmlschema-1-20000922 Latest version: http://www.w3.org/TR/xmlschema-1, W3C Recommondation, 2-May-200[XML-Sch2]XML Schema Part2:Datatypes, Working Draft,22-September-2000 This version: http://www.w3.org/TR/xmlschema-2-20000922 Latest version: http://www.w3.org/TR/xmlschema-2, W3C Recommondation, 2-May-2001[XML]Extensible Markup Language(XML) 1.0, W3C Recommendation,10-February-1998 http://www.w3.org/TR/REC-xml-19980210 Latest version: http://www.w3.org/TR/REC-xml, Extensible Markup Language (XML) 1.0 (Second Edition)[XNR]XML Namespaces, W3C Recommendation,14-January-1999 http://www.w3.org/TR/REC-xml-names[InfoSet]XML Information Set, Working Draft 20-December-1999 http://www.w3.org/TR/xml-infoset[recXPath]. XPath, W3C Recommondation 16-November-1999 http://www.w3.org/TR/xpathModularization of XHTML in XML SchemaWorking Draft (in Developement), 22-March-2001 http://www.w3.org/TR/xhtml-m12n-schema[Set96]R.Sethi:Programming Languages -- Concepts and Constructs, Addison Wesley, 1996
 Lehr- und Forschungseinheit
Lehr- und Forschungseinheit